Universal Object Storage Seeding
Situation
Initial full backup of big datasets to the cloud may take long. Amazon Web Services (AWS) has Snowball Edge service. It is a removable storage they ship to a customer for initial seeding. That stourage should be returned back to AWS when data is on it. After that, AWS will seed the data to the storage and it will be ready for further incremental usage.
Other providers have their options to seed data. Cloudberry Backup supports out-of-the-box AWS Snowball, but not for other S3 compatible providers. CloudBerry requires certain folders / files structure of is backups. That structure should be created. Below you will see the steps to prepare your data for the Snowball injection.
Solution
Seeding to object storage can be done over S3 Compatible appliance (Virtual Machine) that customers can download and use as middleware between data and colon supported storage (e.g. NAS with linux file system).
Prerequisites
- Download Cloudberry S3 compatible appliance;
- It is tiny linux machine (Debian 8 jessie)
- It is with based system, no UI
- It is with SSH server
- It is with Minio S3 compatible as our seeding middleware
- It is with v2/v4 S3 API signature support.
- Get NAS (or other storage) with file system that supports colon (consult with your storage provider / NAS supplier);
- Prepare your backup strategy (e.g. backup plan groups, consider encryption / compression policies).
Appliance Configuration
S3 compatible appliance is available in VMware Virtual Machine (OVF 2.0) form-factor. Deploy new virtual machine (can be on one of your VMware ESXi or VMware Workstation). Request another form-factor from sa-team@cloudberrylab.com or if you experience issues with downloading this archive once this one does not work or you don’t have certain facilities to run it.
Start the Virtual Appliance and login with cloudberry:Pa$$w0rd. Upgrade your permissions to root if you experience issues with mounting shares (Yes, this is not a best practice) with root:Pa$$w0rd. Mount your remote share (NAS) with the following example:
mount -t nfs your_IP:/folder /mnt/nas/
ls /mnt/nas // check your mount, create / delete files / folders, just to make sure you have permissions
Go to your home (cloudberry user) directory (/home/cloudberry/) and execute the following:
./minio server /mnt/nas/
Endpoint: http://:9000 http://:9000
AccessKey:
SecretKey:
Region: us-east-1
Browser Access:
http://:9000 http://:9000
Command-line Access: https://docs.minio.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://:9000
Object API (Amazon S3 compatible):
Go: https://docs.minio.io/docs/golang-client-quickstart-guide
Java: https://docs.minio.io/docs/java-client-quickstart-guide
Python: https://docs.minio.io/docs/python-client-quickstart-guide
JavaScript: https://docs.minio.io/docs/javascript-client-quickstart-guide
This means, that you have your S3 compatible server within Appliance running with v4 Signature support. Now we need proxy, do the following:
cd $GOPATH/bin
./s3v2tov4-proxy -l :8000 -f http://localhost:9000 -access -secret
If you don’t see any errors, you are set now with S3 compatible middleware and ready to do rest of configuration in Cloudberry lab products.
Configuration of CloudBerry Backup
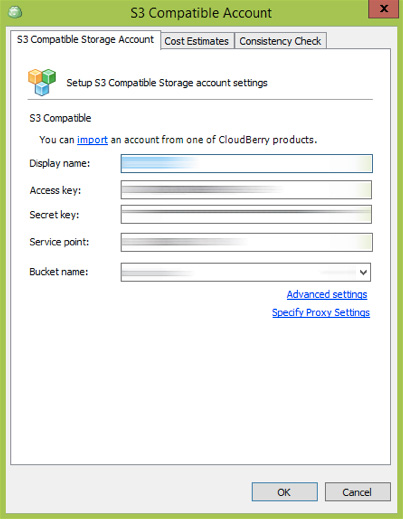
Download and install (if you haven't already) CloudBerry Backup for Windows / macOS / Linux. Configure your storage account:
Next step is to configure your backup plan (Image Based, File / folder etc), use your recently created storage account for this. Run backup plan and make sure you have data written to your NAS storage and the structure is not changed (you should be able to see colon element in folders / files). For example in path with files where disk letter (e.g. C:). For example:
cloudberry@cloudberry:/mnt/qnap/backups/backup/CBB_DC$ tree .
.
|-- C:
| |-- :acl:
| | `-- 20160902151528
| | `-- 8bae0af739186d8461df58591a9720f1
| `-- Distribs
| |-- bootable.iso:
| | `-- 20160726133432
| | |-- bootable.iso
Seeding is ready and can be shipped to storage provider.
Reuse seeding and keep incremental runs
Your storage provider should offload data to datacenter and provider credentials and endpoint to connect. Configure new object storage endpoint accordingly (in the similar way we did for the seeding storage). Reconfigure your backup plan by changing storage account. You may need to “Syncronize Repository” in «Tools» → «Options» → «Repository» in order to list existing backup data and fit it with Cloudberry SQLite backend.