Amazon S3 Glacier Storage Classes and Glacier Vault Differences Explained
This article brings you a better understanding of the difference between Amazon S3 Glacier storage classes for the regular S3 storage and the legacy Glacier Vault storage.
With the introduction of the Amazon S3 Glacier storage class, some confusion persisted among AWS customers: what exactly was changed, and how to apply these changes properly? Below are a few simple answers to state the most notable points of difference between the Glacier-related AWS storage solutions.
This article covers the following topics:
- Amazon Glacier Vault Storage
- S3 Glacier Flexible Retrieval Storage
- S3 Glacier Instant Retrieval Storage
- S3 Glacier Deep Archive Storage
- Amazon Glacier Storage solutions support in MSP360 (CloudBerry) Backup products and services
Glacier Vault Storage
Glacier Vault is an archive storage solution independent from AWS S3. It uses storage containers named vaults (opposed to S3 buckets) and its own set of APIs for data uploading and retrieving.
As the storage price is cheaper compared to S3, data retrieval is more expensive and time-consuming. However, both of these properties can be influenced by applying a retrieval policy specific to the use case: either a standard, bulk (aimed at cost-effective retrieval of big datasets), or expedited policy (aimed at faster retrieval of data).
Once uploaded, the dataset stored in the Glacier vault can be listed by requesting the metadata with an API request. Typically, it takes about 4 hours to retrieve metadata which in turn clears the way for full or partial retrieval of the dataset (that requires additional time in correspondence with the chosen retrieval policy).
The vault where the data is stored can also be applied with a vault lock which prevents locked data deletion for a specified period.
Despite Glacier Vault storage is no longer actively developed by Amazon, it is still functional.
At MSP360, we recommend to our clients use more modern Glacier storage solutions described below, and the ones adequate to their particular use cases as well as data retrieval time and cost expectations.
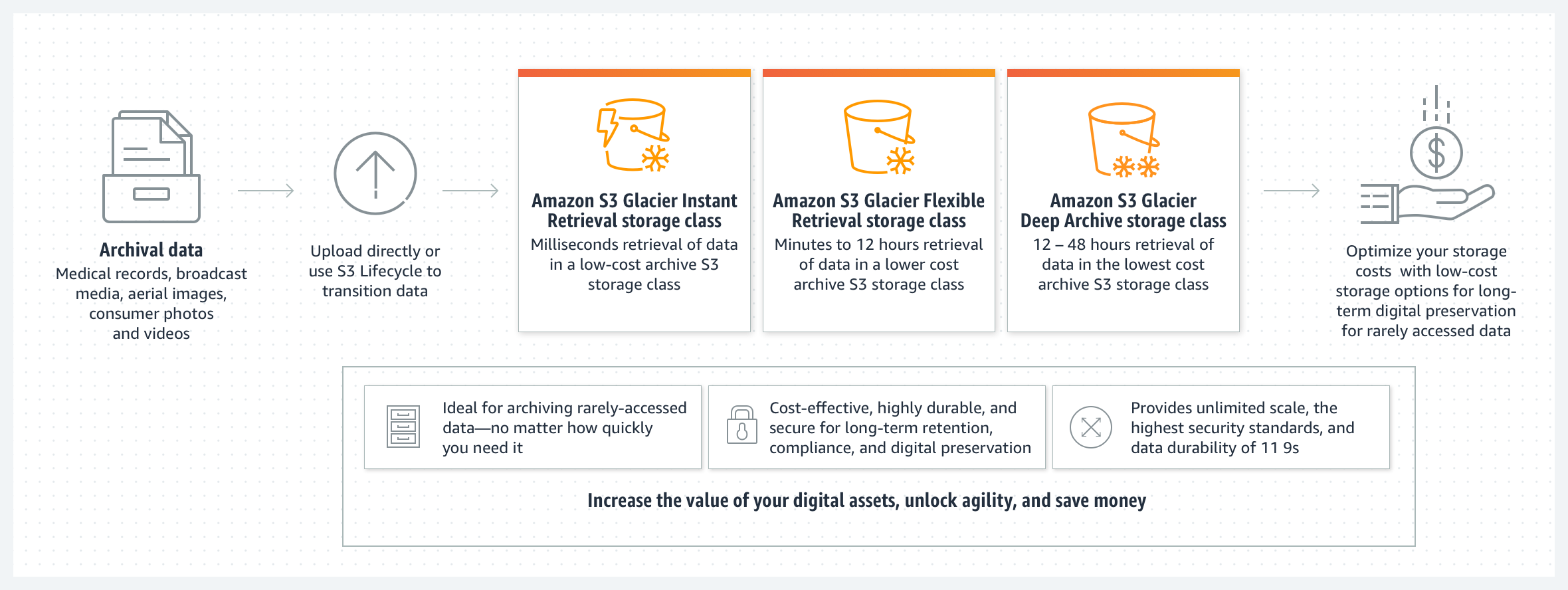
S3 Glacier Flexible Retrieval Storage Class
As the name implies, the Amazon S3 Glacier Flexible Retrieval (formerly known as just "S3 Glacier") is a combination of both S3 and Glacier storage solutions into one ecosystem with a single set of APIs. S3 Glacier Flexible Retrieval uses S3 APIs for data management. It also uses the S3 storage bucket as a repository for metadata of the Glacierbased cold-stored objects, making the metadata retrieval (and subsequently, data listing), much faster when compared to the legacy Vault-based Glacier storage.
The S3 Glacier Flexible Retrieval is no longer a stand-alone storage solution. It is integrated as a distinct storage class within the S3 list of storage classes dedicated to long-term data storage. Data can be moved to the S3 Glacier Flexible Retrieval storage class after a certain period of time by using the S3 data lifecycle policies.
To learn more, refer to the Lifecycle Policies chapter of our help.
From the backend perspective, the S3 Glacier Flexible Retrieval is similar to Glacier Vault storage, with practically the same data retrieval approach and pricing (that includes the standard, bulk, or expedited data retrieval policies). The data retrieval duration can take up to 12 hours in this storage class. However, close integration with S3 APIs benefits the usability of this storage solution.
As the vaults in the S3 Glacier Flexible Retrieval storage class are no longer user-managed, an object lock can be applied to S3 buckets affiliated with S3 Glacier Flexible Retrieval-stored data in order to secure it from preemptive deletion if necessary.
To learn more about AWS S3 Glacier Flexible Retrieval, refer to the Amazon S3 Glacier Flexible Retrieval section at aws.amazon.com
S3 Glacier Instant Retrieval Storage Class
A recently introduced storage class, S3 Glacier Instant Retrieval is mostly similar to the above-explained S3 Glacier Flexible Retrieval storage class. However, a critical difference between the two lies in the Instant Retrieval storage class' ability to request and download the correspondingly stored data with a delay measurable in just milliseconds (as opposed to hours-to-days in other S3 Glacier storage classes).
The S3 Glacier Instant Retrieval storage class can be considered an interim solution between the S3 One Zone-Infrequent Access and the S3 Glacier Flexible Retrieval storage classes. While the Instant Retrieval storage class is still a low-cost cold storage solution, its data retrieval pricing is the highest among the Glacier-family of S3 storage classes.
To learn more about AWS S3 Glacier Instant Retrieval, refer to the Amazon S3 Glacier Instant Retrieval section at aws.amazon.com
S3 Glacier Deep Archive Storage Class
The S3 Glacier Deep Archive is the cheapest cold storage solution AWS has to offer. A slower retrieval speed and a higher retrieval cost are the implications of the lowest offered long-term data storage cost. Retrieval policies are reduced to just standard and bulk, with no expedited option available. The duration of the data retrieval can last up to 48 hours.
To learn more about S3 Glacier Deep Archive storage class, refer to Amazon S3 Glacier Deep Archive section at aws.amazon.com
Below you can see a brief overview of the currently offered Amazon S3 Glacier storage classes (Credit: Amazon Web Services Documentation):
State of the Amazon Glacier storage solutions support in MSP360 (CloudBerry) Backup products and services
- Glacier Vaults storage is not supported in Managed Backup Service
- Glacier Vaults storage is no longer supported in standalone MSP360 (CloudBerry) Backup. However, the prospect of legacy backup retrieval can be a subject for evaluation and investigation on a case-by-case basis via the MSP360 technical support team
- AWS S3 Glacier Flexible Retrieval, Instant Retrieval, and Deep Archive storage classes are supported in both Managed Backup Service and standalone MSP360 (CloudBerry) Backup software. Backups can be aimed directly at the S3 Glacier Flexible Retrieval / Instant Retrieval / Deep Archive storage class (when the backup plan is set up) or moved there later using the data lifecycle policies