Retries Explained
About Retries
A retry is a specific approach of error processing that analyzes the response to a request and if a known failure response is received invokes a repeat for a specified number of attempts and a specified period.
Most commonly retries are used for errors connected with remote server responses or network issues such as '500 Internal Server Error'. Also, HTTP errors, particular network errors (for example, 'The remote hostname cannot be resolved' or timeout errors) are generally retriable.
Find below a list of retriable errors used in MSP360 products:
Retryable Requests to Managed Backup Server
These retriable errors have constant values and cannot be configured.
The following errors upon requesting Managed Backup server are retried every 1 minute within 4 hours:
- 503 ServiceUnavailable. This server response usually occurs if any software instance addresses the Managed Backup server (requests temporary credentials, a license is checked, sends notifications, etc.) while servers are under maintenance.
The following errors are retried every 5 seconds within 15 minutes:
- WebExceptionStatus.ConnectionClosed
- WebExceptionStatus.ConnectFailure
- WebExceptionStatus.ReceiveFailure
- WebExceptionStatus.SendFailure
- WebExceptionStatus.KeepAliveFailure
- WebExceptionStatus.Pending
- WebExceptionStatus.Timeout
- WebExceptionStatus.NameResolutionFailure
- InternalServerError (500)
- BadGateway (502)
- GatewayTimeout (504)
| Top |
Storage Retryable Errors
The following errors received from storage are retried.
Connection errors:
- CacheEntryNotFound
- ConnectFailure
- ConnectionClosed
- KeepAliveFailure
- NameResolutionFailure
- Pending
- PipelineFailure
- ReceiveFailure
- SecureChannelFailure
- SendFailure
- Timeout
- UnknownError
- SocketException
HTTP Errors:
- 408 Request timeout
- 429 Too many requests/Slow down. This retry is infinite
- 500 Internal server error
- 502 Bad gateway
- 503 Service unavailable. This retry is infinite
- 504 Gateway timeout
Backblaze B2-specific errors:
- 400 "not an active upload:"
- 400 "No active upload for"
AWS S3-specific errors:
- XAmzContentSHA256MismatchException. The data part hash checksum is invalid
Non-Configurable Retries
If network issues occur, a current operation (the one that is taking place at the moment of network issue occurrence) will be retried according to the settings as configured (3 times by default), then the plan will be put on hold for some period (1 minute by default), then retried again starting by configured retries. This sequence will be repeated for 100 minutes by default. If network issues persist, a plan fails with an appropriate error. If a network connection is re-established within this 100-minute period and then occurs again, a 100-minute period is reset.
Plan Restarts
This applies to the legacy backup format only
For plans in legacy backup Format, the logic is a bit different. Each file is uploaded/downloaded by its own upload or download operation. If network issues continue occurring, each currently running operation is retried according to configured settings (3 times by default). If no successful retries occur, then the operation is put on hold for 1 minute, then is run again. This loop is repeated 100 times in total, then the plan fails with an appropriate error.
| Top |
Configure Retries
You can configure retry settings. The configurable retry settings apply to failed HTTP requests or some failed network share requests (i.e., storage retries).
To configure retry settings, proceed as follows:
- In Tools, click Options.
- Switch to the Connection tab.
- Set the number of attempts and the period between retry attempts.
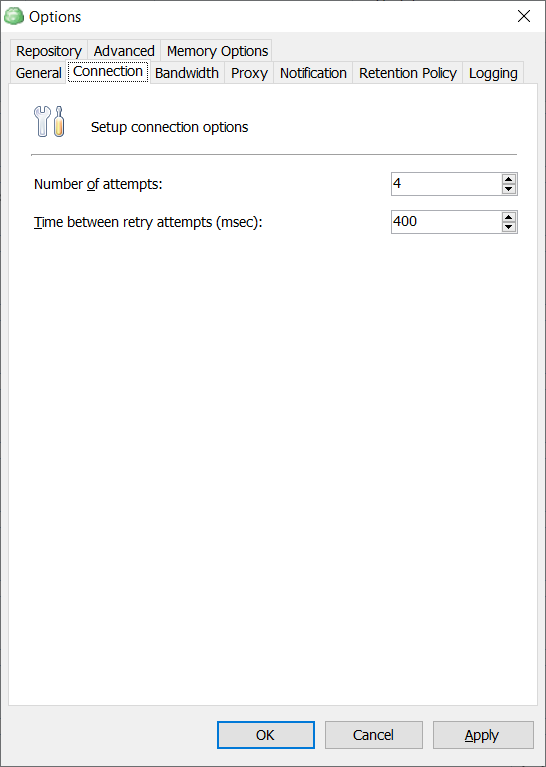
Note that the number of attempts is not the number of retries. It is the total number of attempts. Thus, if you set the number of attempts as 5, this means the original attempt and 4 retries
In some cases, the 'Time between retry attempts' value is calculated based on an exponential backoff strategy. The value defines a delay before the first retry, and the next delay before the next retry is doubled. For example, if the 'Time between attempts' is 400 msec, the first retry will be executed in 400 msec, the second will be executed in 800 msec, the third will be executed 1600 msec, etc.
In some other cases, the value is linear. For example, if upon a restore a data part is downloaded from storage and the hash sum is invalid for some reason, every retry of reading this data again part will be executed after 400 msec
For some retriable errors, the number of retries is unlimited. These are errors that the server reports to make the client reduce the request rate limit:
- 503 Service unavailable
- 429 Too many requests/Slow down
| Top |